Python 包
什么是包
在之前的学习中,我们已经了解了模块的概念,即将项目模块化或文件化的方式。为了更好地组织模块并提供名称层次结构,我们引入了包的概念,即由英文单词 "package" 翻译而来。下面通过一个场景来认识包的概念。
假设我们的电脑中有许多 Word 文件,分布在不同的盘符下,比如有的在 C ��盘,有的在 D 盘。在需要找到某个文件时可能会变得非常麻烦。通常情况下,我们会创建一个文件夹,将具有相关信息的 Word 文件放到同一个文件夹下。这样做可以更方便地管理这些文件。如下图所示:
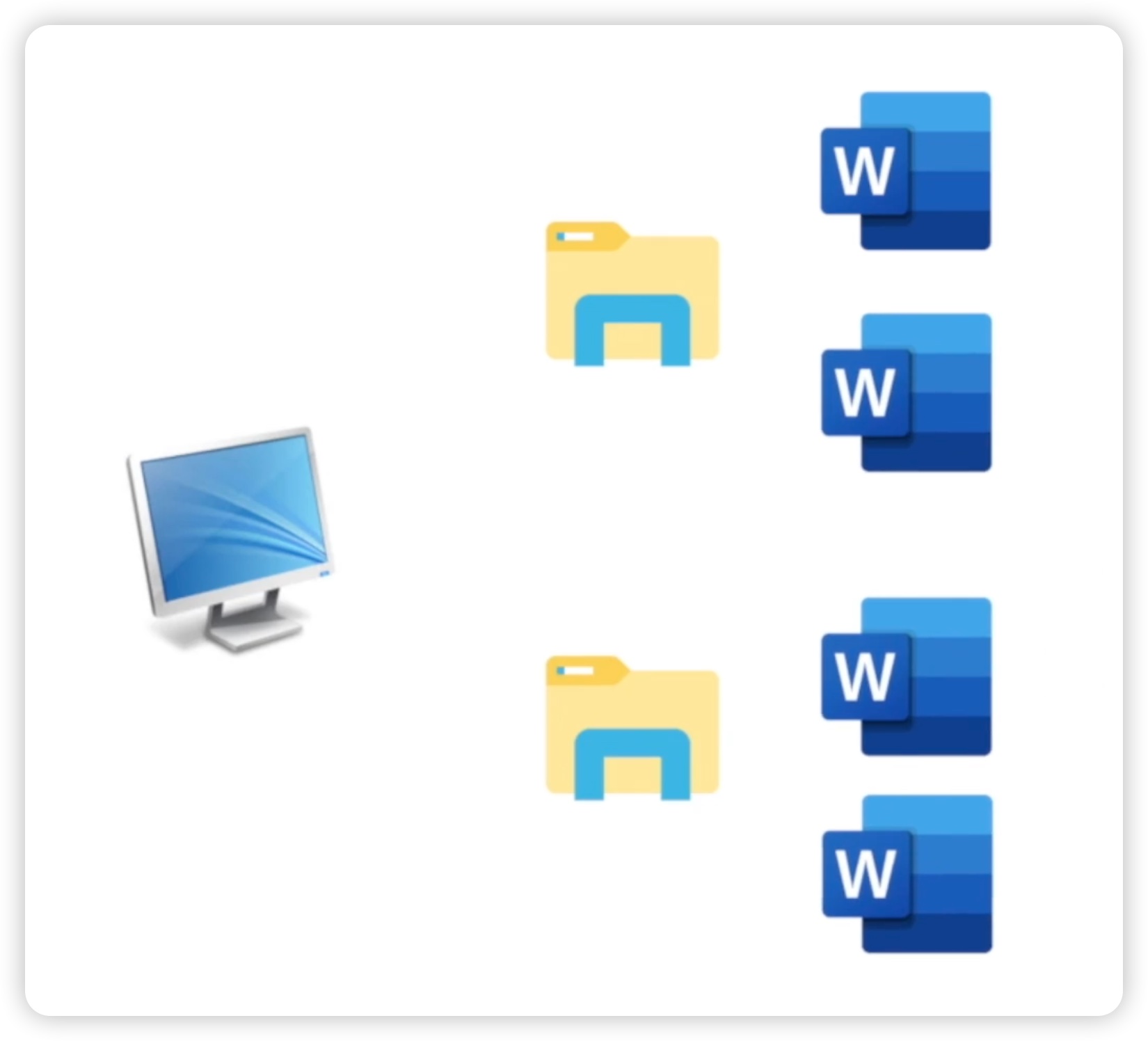
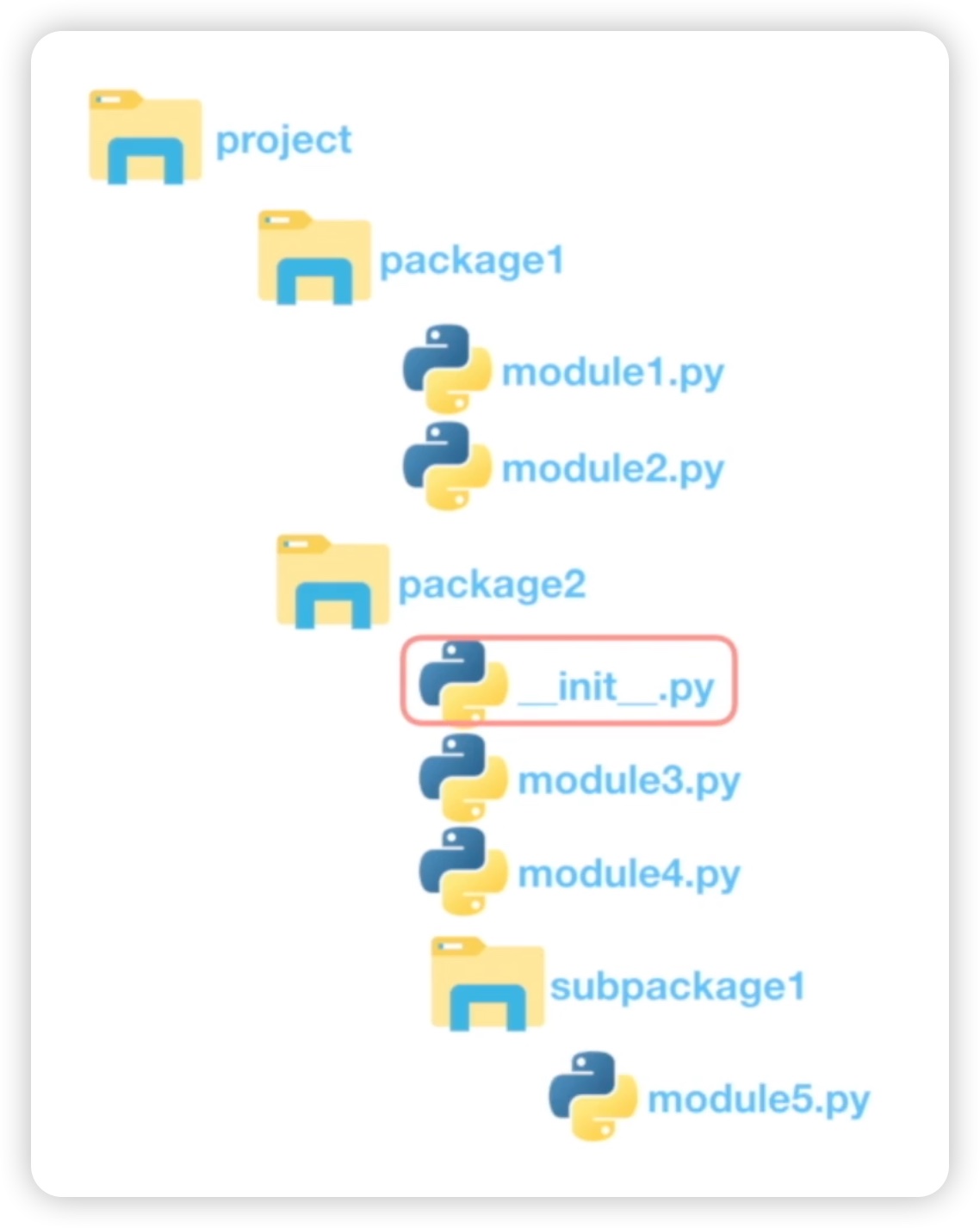
类似地,我们之前提到一个模块就是一个 Python 文件。当项目越来越大时,会使用更多的模块。为了方便管理,我们会采用目录的形式,也就是使用文件夹来组织这些 Python 文件。举例来说,在一个名为 "project" 的顶级文件夹下,我们可以创建两个文件夹 "package1" 和 "package2"。每个文件夹下可以包含多个 Python 文件,这些文件就是模块。通过将相关的模块放到同一个文件夹中,如 "package1" 和 "package2",我们可以更轻松地管理它们。这里的 "package1" 和 "package2" 就是包的概念。因此,包就是一个有层次的文件目录结构。如下图所示:

至少需要一个文件夹才能称之为包,文件夹下可以包含多个 Python 文件。需要注意的是,在许多图书或教程中,一直强调文件夹下必须有一个名为 "__init__.py" 的文件才能称之为包。如下图所示:
然而,从 Python 3.3 开始,这个 "__init__.py"文件可以省略。因此,即使像 "package1" 这样的文件夹下没有 "__init__.py"文件,它依然可以被视作包。
为�了验证这一点,我们可以创建一个新的文件夹,在其中创建一个名为 "package1" 的文件夹。接下来我们再创建一个包,选择了 "Python package",如下图所示:
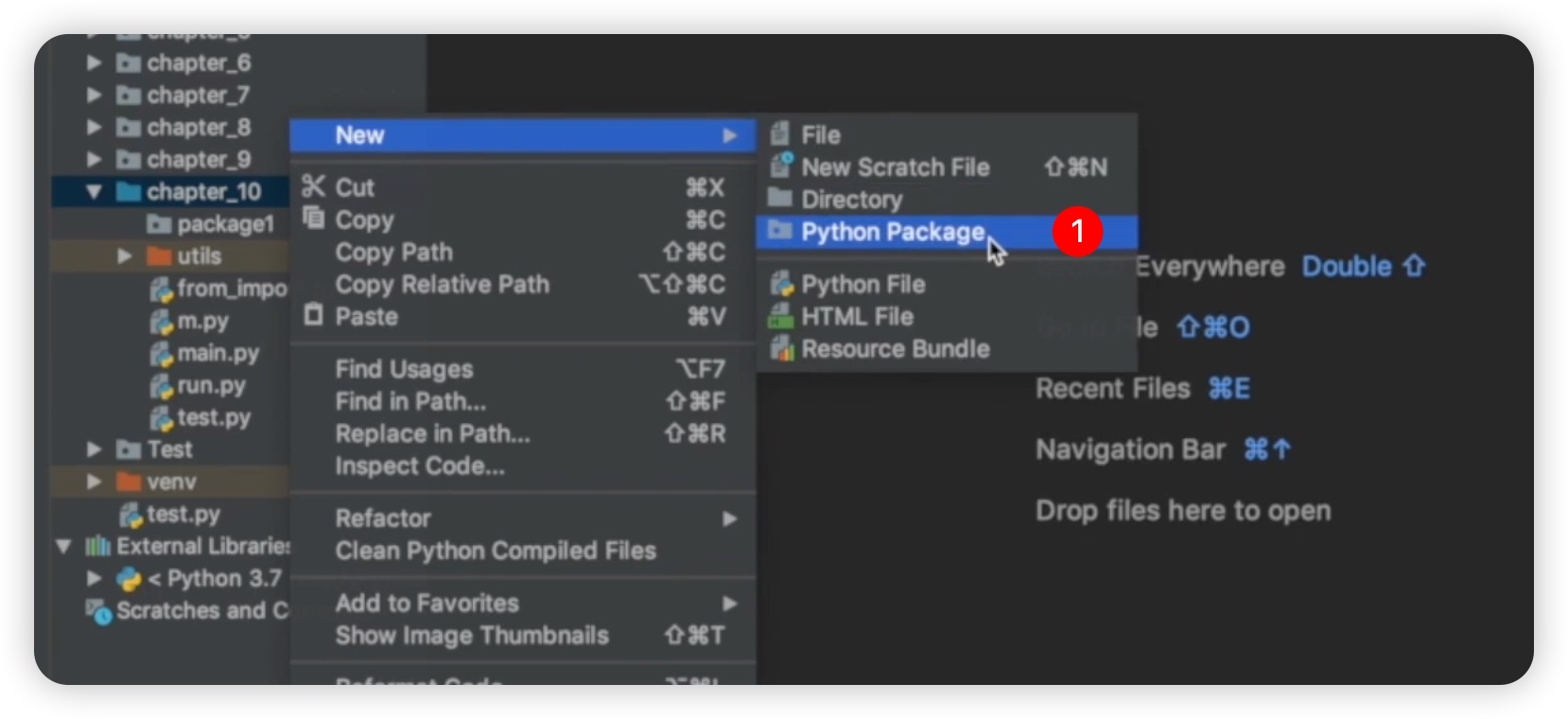
我们创建了一个名为 "package2" 的文件夹。在创建完成后,我们会注意到与之前的 "package1" 有所不同,即在 "package2" 文件夹下自动创建了一个名为 "__init__.py" 的文件。这个文件是一个空文件,没有任何代码。这意味着当我们创建一个包时,系统会自动创建一个 "__init__.py" 文件。相比之下,之前的 "package1" 只是一个文件夹,没有额外的文件。如下图所示:
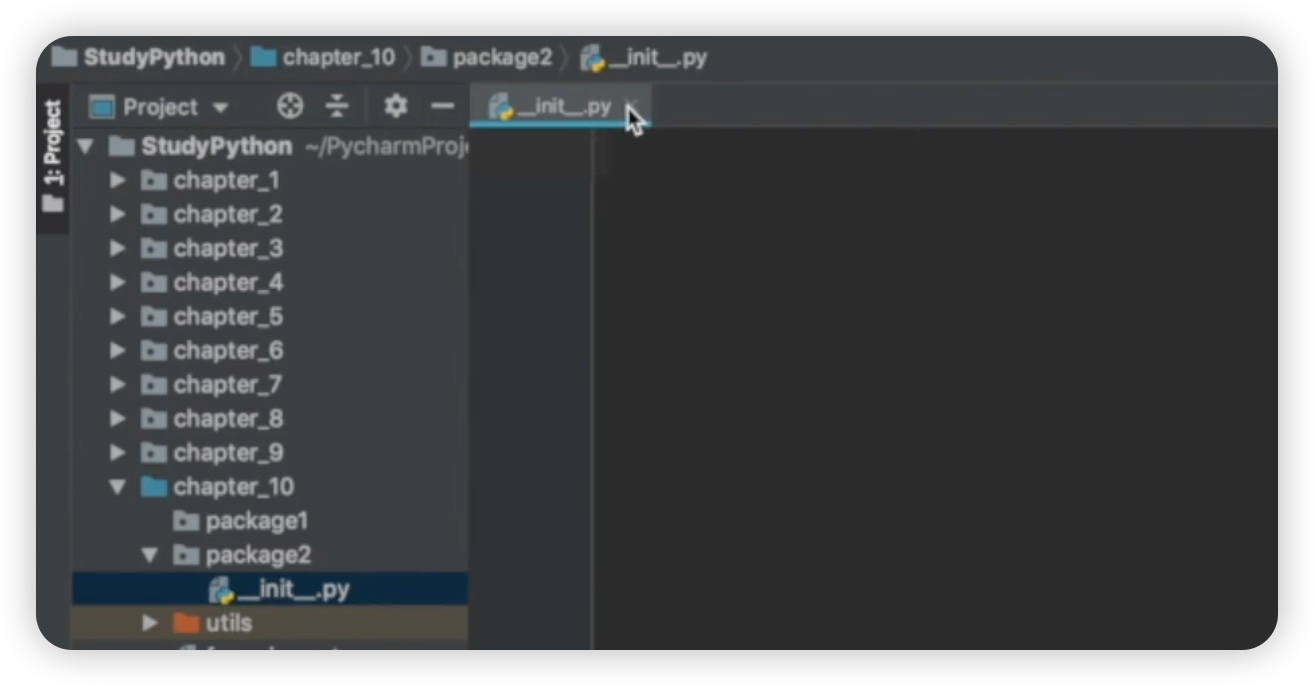
接下来,我们需要验证一下 "package1" 和 "package2" 是否都是包。在 "package1" 下,我们创建了两个 Python 文件,分别命名为 "module1" 和 "module2";而在 "package2" 下,我们创建了两个 Python 文件,分别命名为 "module3" 和 "module4",此外还有一个 "__init__.py" 文件。如下图所示:
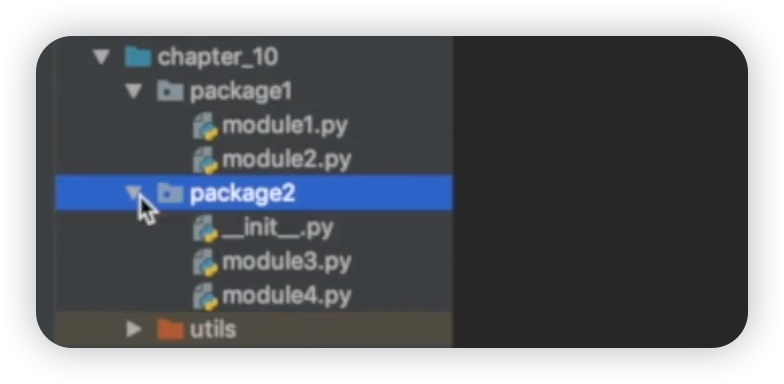
然后,我们再创建了一个 Python 文件 "my_main.py",位于和 "package1"、"package2" 同级的位置。接下来,在 "my_main.py" 文件中,我们导入了 "package1" 下的 "module1" 和 "package2" 下的 "module3" 进行测试。代码如下��:
# 从 package1 中导入 module1 模块
from package1 import module1
# 从 package2 中导入 module3 模块
from package2 import module3
# 打印 module1 模块的属性列表
print(dir(module1))
经过测试,我们发现 "module1" 是一个模块,我们使用了 dir 属性来查看它的属性,发现其中包含 "__name__" 和 "__package__" 属性。
输出结果如下图所示:

我们尝试输出 "module1" 的名称以及它的包属性,代码如下:
# 从 package1 中导入 module1 模块
from package1 import module1
# 从 package2 中导入 module3 模块
from package2 import module3
# 打印 module1 模块的属性列表
print(dir(module1))
# 打印 module1 模块的名称属性
print(module1.__name__)
# 打印 module1 模块的包属性
print(module1.__package__)
结果显示它的名称是 "package1.module1",属于 "package1" 包。同样地,我们可以验证 "package2"。代码如下:
# 从 package1 中导入 module1 模块
from package1 import module1
# 从 package2 中导入 module3 模块
from package2 import module3
# 打印 module1 模块的属性列表
print(dir(module1))
# 打印 module1 模块的名称属性
print(module1.__name__)
# 打印 module1 模块的包属性
print(module1.__package__)
print(module3.__package__)
我们尝试输出 "module3" 的包属性,结果显示为 "package2"。这说明 "module3" 属于 "package2" 包。这也证明了 "package1" 和 "package2" 都是包,即使 "package1" 下没有 "__init__.py" 文件,依然被视作一个包。
初始化文件的作用
在前一节课中,我们已经详细介绍了包的概念,并且特别强调了在一个文件夹下,是否有双下划线 init.py 文件决定了它是否是一个包。比如说,如果一个文件夹下有 __init__.py 文件,那么它就是一个包,就像这里的 package2 一样。然而,即使没有 __init__.py 文件,它同样也被视为一个包,就像这里的 package1 一样。那么__init__.py 文件究竟是什么呢?本节我们就来介绍一下 __init__.py 文件的作用。
在学习面向对象的时候,我们曾介绍过,在一个类中,如果有一个名为 __init__ 的方法,那么这个方法就是初始化方法。它的作用是在我们实例化这个对象的时候自动执行这个初始化方法。类似地,当我们调用一个包的时候,如果这个包中包含了 __init__.py 文件,那么在调用这个包的时候会自动执行这个 __init__.py 文件。

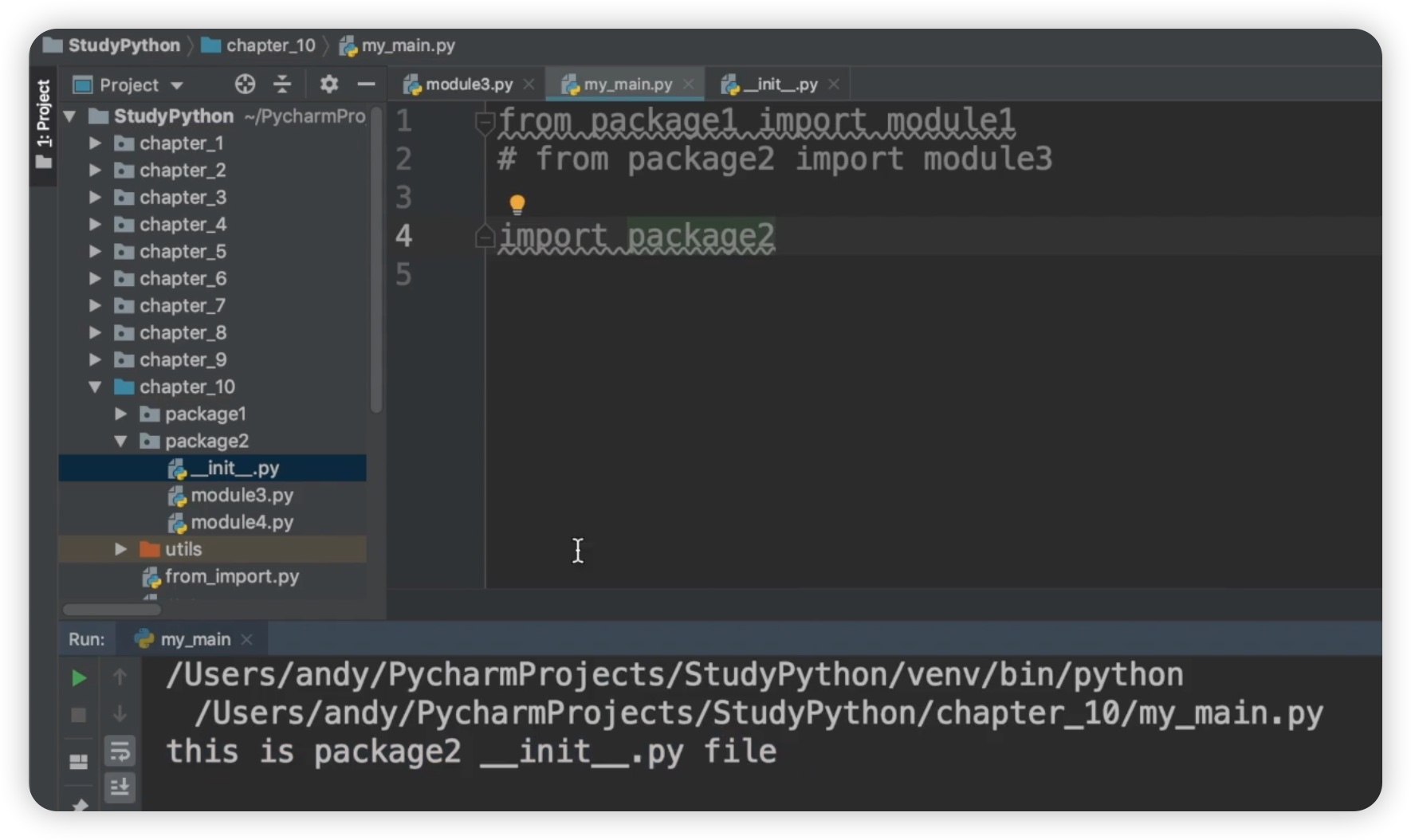
下面我们通过代码来演示这个特性。在 package2 下有一个 __init__.py 文件,这个文件中没有任何代码。现在我们来输出一下:"this is package2 __init__.py 文件"。然后我们把它关掉,再来看,在 package2 下有一个 module3 和 module4。在module3.py文件中输出一下:"this is module3"。好,现在我们来调用这个 package2 下面的 module3 模块,看一下会有什么效果。在my_main.py中输入如下代码:
from package1 import module1
from package2 import module3
输出结果:
this is package2 __init__.py file
this is module3.py file
看到这里的输出结果,首先输出的是 "this is package2 __init__.py 文件"。那么也就是说输出的是 __init__.py 文件中的代码。接下来才输出 "this is module3.py 文件",也就是这里的 module3。这个效果就和我们面向对象中的初始化方法非常相似。当实例化的时候会优先执行初始化方法。那在包中呢,这里的 __init__.py 文件就在调用这个包的时候先去这个包下面查找是否有这个 __init__.py 文件。如果有的话,先执行 __init__.py 文件。所以,这里的 __init__.py 文件也被称之为初始化文件。
我们可以这样来测试一下:直接来导入 package2,再来运行。同样的,它也会自动调用这里的 __init__.py 文件。所以说,这是一个初始化文件。
在确定了这一特性后,我们可以考虑在哪些情况下会用到这个 init.py 文件。首先是在我们需要使用 import * 导入所有内容时,就可以利用 init.py 文件。接下来我们将在代码中演示这一特性。在 module3.py 中,我们将定义几个函数。首先是加法函数,直接输出 "this is add function"。然后是减法函数,接着定义乘法和除法函数。代码如下:
# 打印模块3文件的声明
print("this is module3.py file")
# 定义一个执行加法的函数
def add():
print("this is add function")
# 定义一个执行减法的函数
def subtraction():
print("this is subtraction function")
# 定义一个执行乘法的函数
def multiplication():
print("this is multiplication function")
# 定义一个执行除法的函数
def division():
print("this is division function")
接着看 module4.py,在这里我们定义了一个类 Student。代码如下:
# 定义一个学生类
class Student(object):
# 初始化方法,接收一个名字参数
def __init__(self, name):
self.name = name # 将名字赋值给实例变量
# 定义一个获取学生姓名的方法
def get_student_name(self):
print(f"学生姓名是{self.name}") # 打印学生的姓名
接下来,我们使用常规方式调用 module3 和 module4。我们在my_main.py中填写代码:
# 从 package2 模块中导入 module3 下的所有内容
from package2.module3 import *
# 从 package2 模块中导入 module4 下的所有内容
from package2.module4 import *
add()
输出结果如下图:
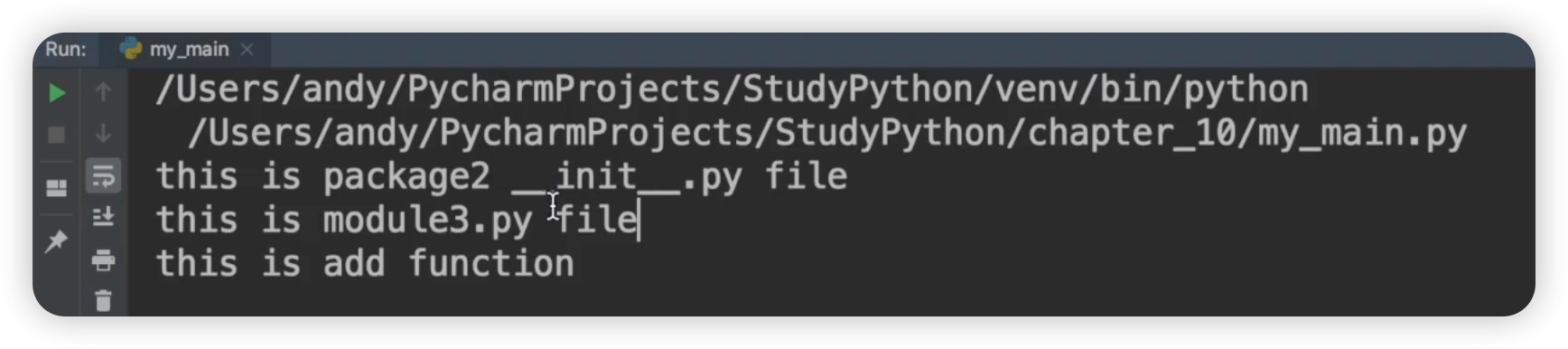
首先执行 init.py 文件,然后输出 module3 中的内容。接着才会输出我们调用的方法,比如 add。同样的,我们也可以调用减法、乘法和除法。然后我们再来看 module4,可以调用 Student 类,并实例化一个学生对象,将其赋值给 student。给这个学生对象添加一个名字,因为初始化方法可以接收这个名��字。添加名字后,我们可以使用这个实例化的对象调用相应的方法。代码如下:
# 从 package2 模块中导入 module3 下的所有内容
from package2.module3 import *
# 从 package2 模块中导入 module4 下的所有内容
from package2.module4 import *
# 调用 module3 中的函数
add() # 执行加法函数
subtraction() # 执行减法函数
multiplication() # 执行乘法函数
division() # 执行除法函数
# 创建一个名为 "Andy" 的学生对象
student = Student("Andy")
# 调用学生对象的方法获取学生姓名
student.get_student_name()
运行后,输出一个学生的名字为 "Andy"。以上是最常规的做法,我们调用自己写的模块时,知道这个包下面有 module3 和 module4,以及每个模块下的一些方法�。但有时,我们的包是给别人用的。当别人需要使用我们的包时,他们也需要知道有 module3 和 module4,以及这些模块下的方法。如果模块很多,记住它们就会比较麻烦。所以在这种情况下,我们可以使用 init.py 文件来优化。因为在导入包时会自动执行它。init.py 文件代码如下:
# 从 package2 模块中导入 module3 下的所有内容
from package2.module3 import *
# 从 package2 模块中导入 module4 下的所有内容
from package2.module4 import *
这样修改后,我们在my_main.py中不直接调用模块了,而是直接调用具体的方法,从包下导入 add、substraction、multiplication、division,以及 Student 类。代码如下:
# 从 package2 模块中导入 add、subtraction、multiplication、division 和 Student 类
from package2 import add, subtraction, multiplication, division, Student
# 调用 add 函数,执行加法操作
add()
# 调用 subtraction 函数,执行减法操作
subtraction()
# 调用 multiplication 函数,执行乘法操作
multiplication()
# 调用 division 函数,执行除法操作
division()
# 创建一个名为 "Andy" 的学生对象
student = Student("Andy")
# 调用学生对象的 get_student_name 方法,打印学生姓名
student.get_student_name()
运行后,效果是一样的。
接下来我们看第二个应用场景,我们将介绍如何使用双下划线 __all__ 来选择性地导入模块内容。在初始化文件 __init__.py 中,我们之前是导入了全部内容,即 import *,这样用户就可以使用 module3 和 module4 中的全部方法。然而,有时我们需要加入一些限制,例如有些内容我们不想让用户导入,比如module3.py文件中的一个名为 "test" 的方法,我们不希望用户调用。但是我们又使用了 import *,这意味着用户可以调用每一个方法。此时,我们可以使用 __all__,给它赋一个值,它是一个列表,在列表中添加用户可以调用的 add、subtraction、multiplication 以及 division。这些都是用户可以调用的方法,而 test 不在列表中,说明它是不可被调用的。module3.py文件代码如下:
# 打印模块3文件的声明
print("this is module3.py file")
# 定义 __all__ 列表,用于选择性导入的属性
__all__ = ["add", "subtraction", "multiplication", "division", "test"]
# 定义一个执行加法的函数
def add():
print("this is add function")
# 定义一个执行减法的函数
def subtraction():
print("this is subtraction function")
# 定义一个执行乘法的函数
def multiplication():
print("this is multiplication function")
# 定义一个执行除法的函数
def division():
print("this is division function")
# 定义一个测试函数,不在 __all__ 中,不会被导入
def test():
print("this is test function")
现在让我们来测试一下,在my_main.py代码中直接添加一个 test 方法,看看能否调用它。现在已经给出了一个波浪线提示,如下图所示:
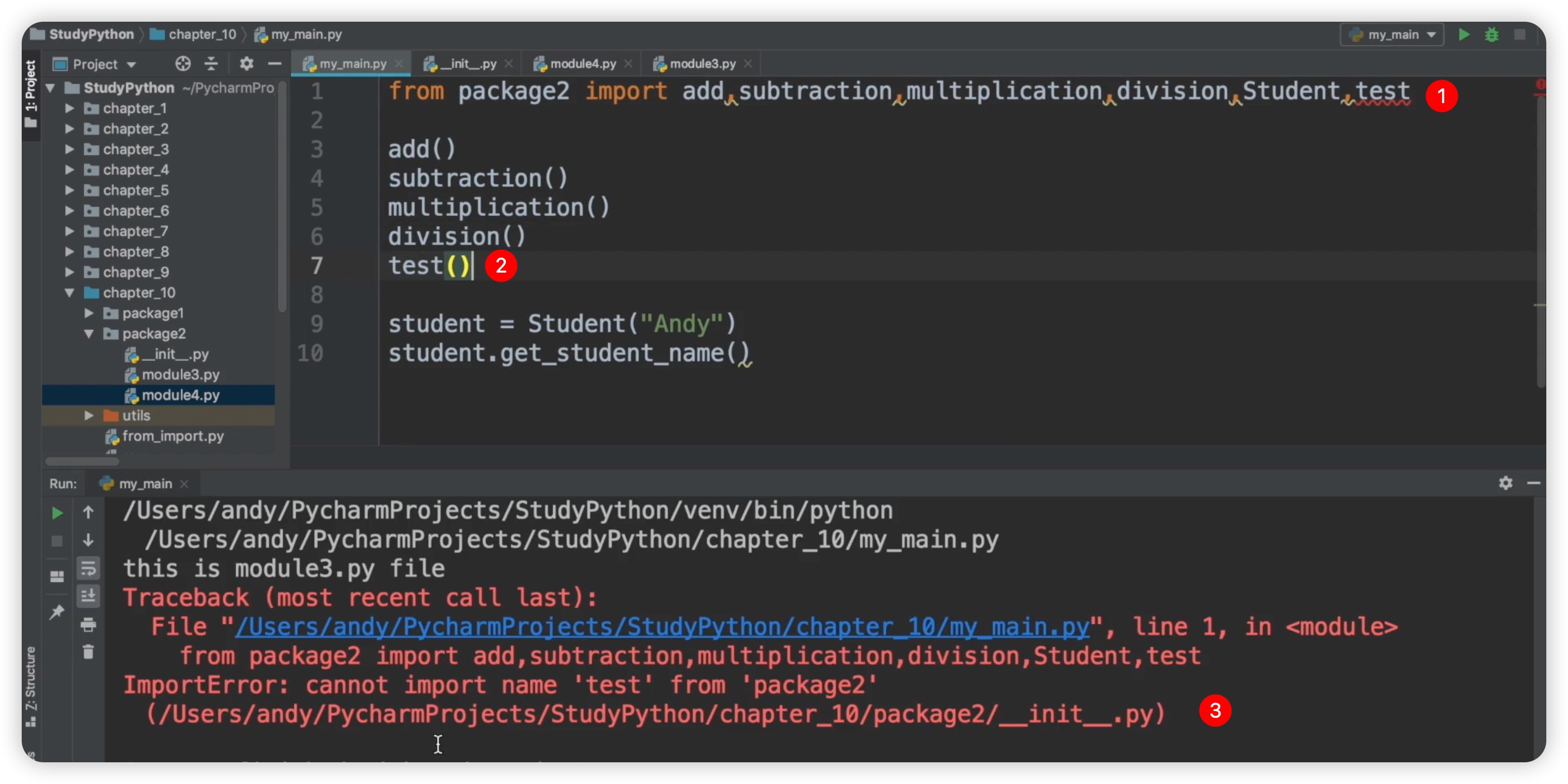
当我们尝试调用它时肯定会报错。果然,不能够导入 test。
对于module3.py的 __all__,如果我们不添加内容,将其设置为空,那么就表示没有一个可以导入的。现在再来运行一下,将会全部报错。如下图所示:
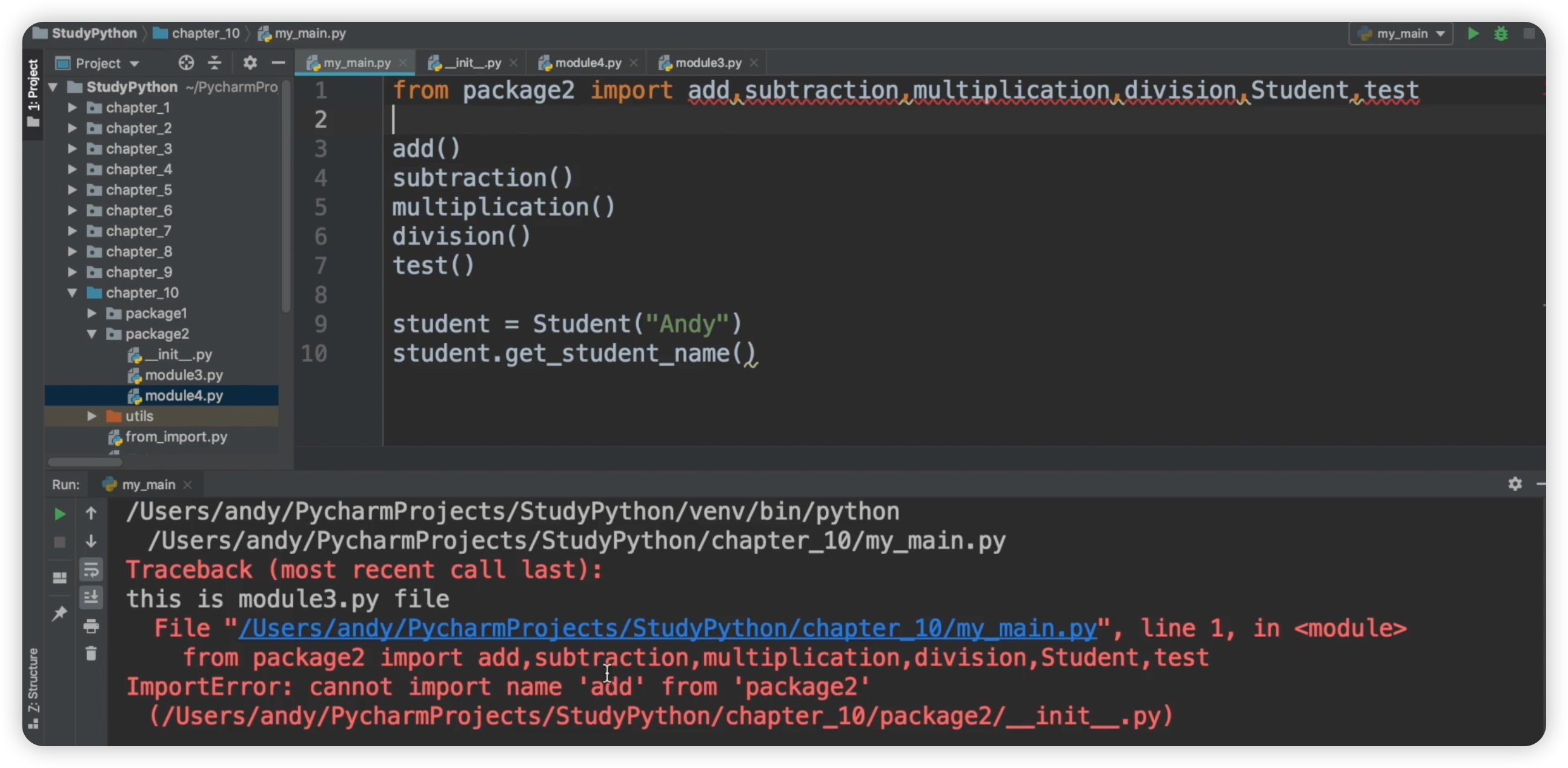
这就是 __init__.py 文件和 __all__ 属性之间的配合使用,允许用户选择性地导入模块中的一些属性。
最后,我们再来看一下应用场景的最后一点,预处理。因为 __init__.py 文件就是一个初始化文件,所以很多预处理的内容都可以写在其中。例如,我们要记录日志,就可以在这个初始化文件中导入模块相关的一些配置。再比如,当我们使用数据库时,也可以在这个初始化文件中导入数据库相关的一些配置。这些内容的使用方法会在后面的项目中再来详细介绍。
绝对路径和相对路径
在本节中,我们将介绍绝对路径和相对路径的概念。这两者都是针对包而言的,因此在没有包的情况下,讨论绝对路径和相对路径就失去了意义。那么,何为绝对路径和相对路径呢?就如同我们在中学时学习的相对速度和绝对速度一样。假设我们的画面中有两辆小车,
它们以100公里每小时的速度行驶。相对于路边静止的物体而言,它们的速度是100千米每小时,这个速度即为其绝对速度。但是相对于两辆车而言,它们的速度是相等的,是并驾齐驱的,因此相对速度为0。相对路径和绝对路径也遵循这样的道理。
在一个项目中的目录结构可以描述为:顶层目录包含两个文件,一个是名为project的文件夹,另一个是名为manage.py的独立Python文件。在project文件夹下有两个包,一个是用于实现项目后台功能的admin包,另一个是用于实现项目前台功能的home包。在home包下还有一个subpackage1包,其中包含两个文件,分别是module5和module6。
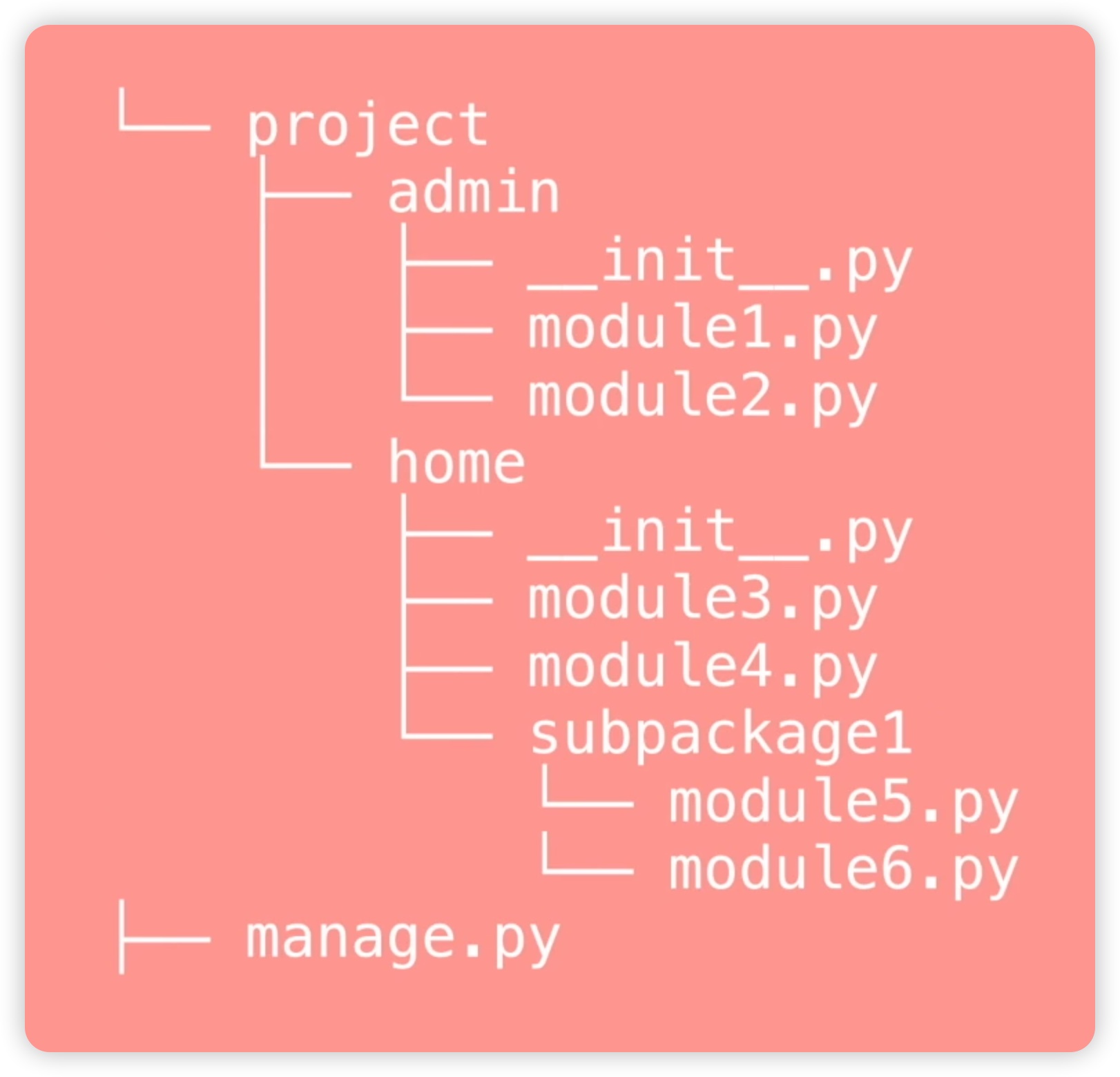
导入包的方式可以使用绝对路径或相对路径。使用绝对路径时,从顶级根目录开始逐级查找,但这种方式在目录结构层级较多时会显得繁琐。相对路径提供了解决这个问题的方法。在相对路径中,可以使用一个点表示当前目录,两个点表示上级目录,三个点表示上上级目录,以此类推。如下图所示:
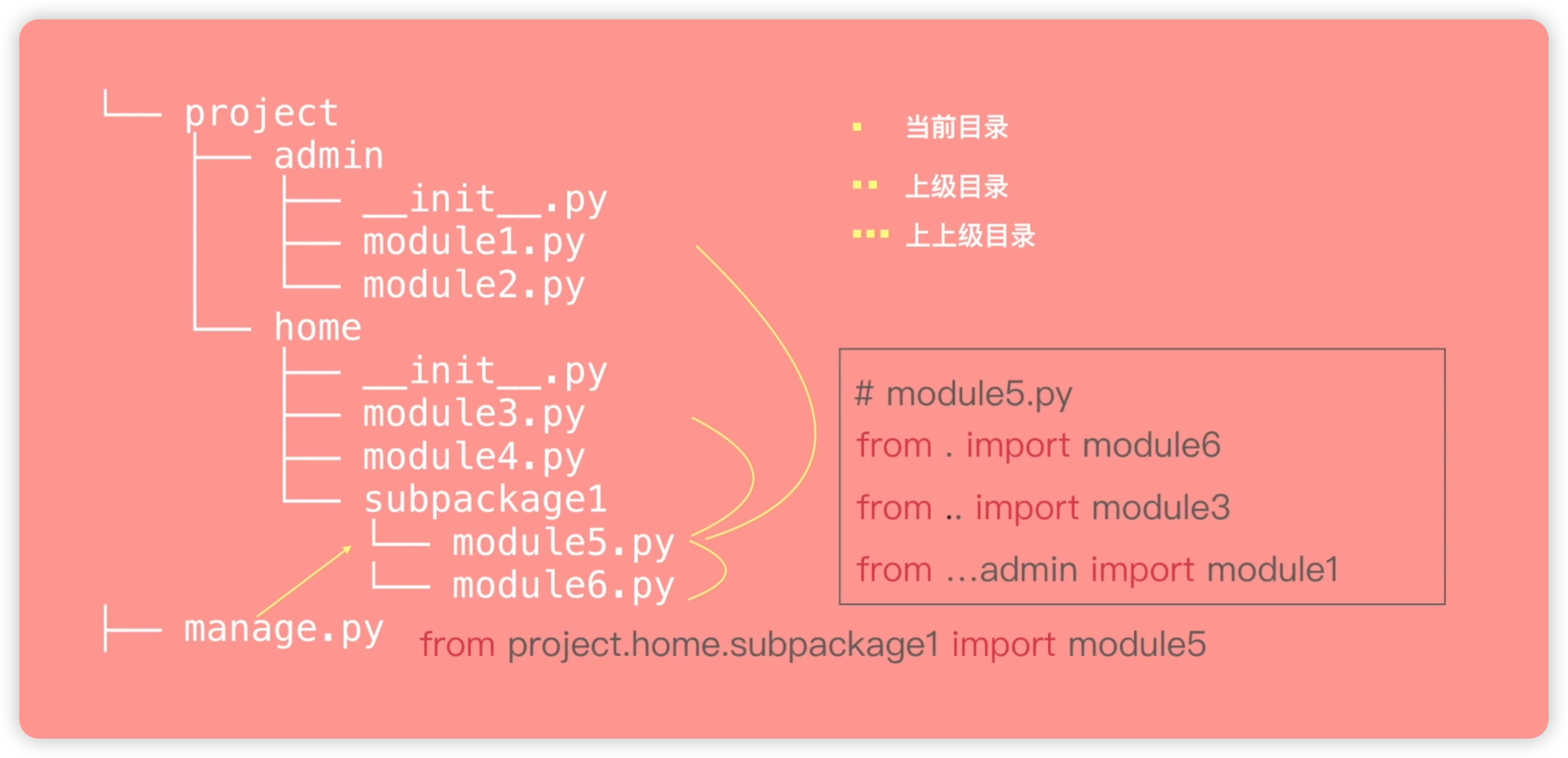
举个例子,在manage.py文件中,如果要导入module5文件,需要使用绝对路径from project.home.subpackage1 import module5。如果在module5中要导入同级的module6,可以使用相对路径,即from . import module6。若要在module5中导入上级目录的module3,需要使用两个点表示,即from .. import module3。若要导入admin模块下的module1,由于admin模块位于上上级目录,可以使用三个点表示,即from ... import module1。然而,在实际开发中,很少会使用上上级的方式,因为在这种情况下,使用绝对路径更为常见。
下面我们将在代码中演示相对路径和绝对路径。首先,在第10章下新建一个Python包,即包,命名为project。创建完成后,在该文件夹下会自动生成一个初始化文件。接着,我们再创建两个包,一个是用于前台的home,另一个是用于后台的admin。这是我们的准备工作。每个包下都有一个初始化文件,如下图所示:
接下来,我们将开始为每个文件夹创建模块。首先,我们创建一个Python文件,命名为"admin_module1"。我们可以继续添加"admin_module2"Python文件。同样地,在"home"文件夹下,我们也可以添加"home_module1和home_module1"。目前,我们在这个项目包下创建了"admin"和"home"两个包文件。对于这些包文件,它们还可以进一步创建子包。在这个基础上,我们再创建一个包,命名为"sub_home"。在这里,我们还可以添加新的文件,例如,命名为"sub_home module1"。如下图所示:
接下来,我们准备创建一个调用文件。在"chapter10"下创建一个Python文件,命名为"manage.py"。在这个文件中,假设我们要调用"sub_home"下的"sub_home module1"文件。如果使用绝对路径,代码如下:
# 导入sub_home_module1模块,使用了绝对路径
from project.home.sub_home import sub_home_module1
为了验证调用是否成功,我们在sub_home_module1.py文件中添加代码,
this is sub_home module1
然后,我们执行"manage.py"文件,查看输出结果是否为"this is sub_home module1"。此时,在"sub_home module1"文件中,我们还需要调用其他模块。例如,我们需要调用与其同级的文件,所以我们创建一个名为"sub_home module2.py"的文件,在其中输出内容为:"this is sub_home module2"。接下来,我们在"sub_home module1"中导入"sub_home module2"。如果要使用绝对路径,代码如下:
# 输出字符串 "this is sub_home_modulel"
print("this is sub_home_modulel")
# 导入sub_home_module2模块,使用了绝对路径
from project.home.sub_home import sub_home_module2
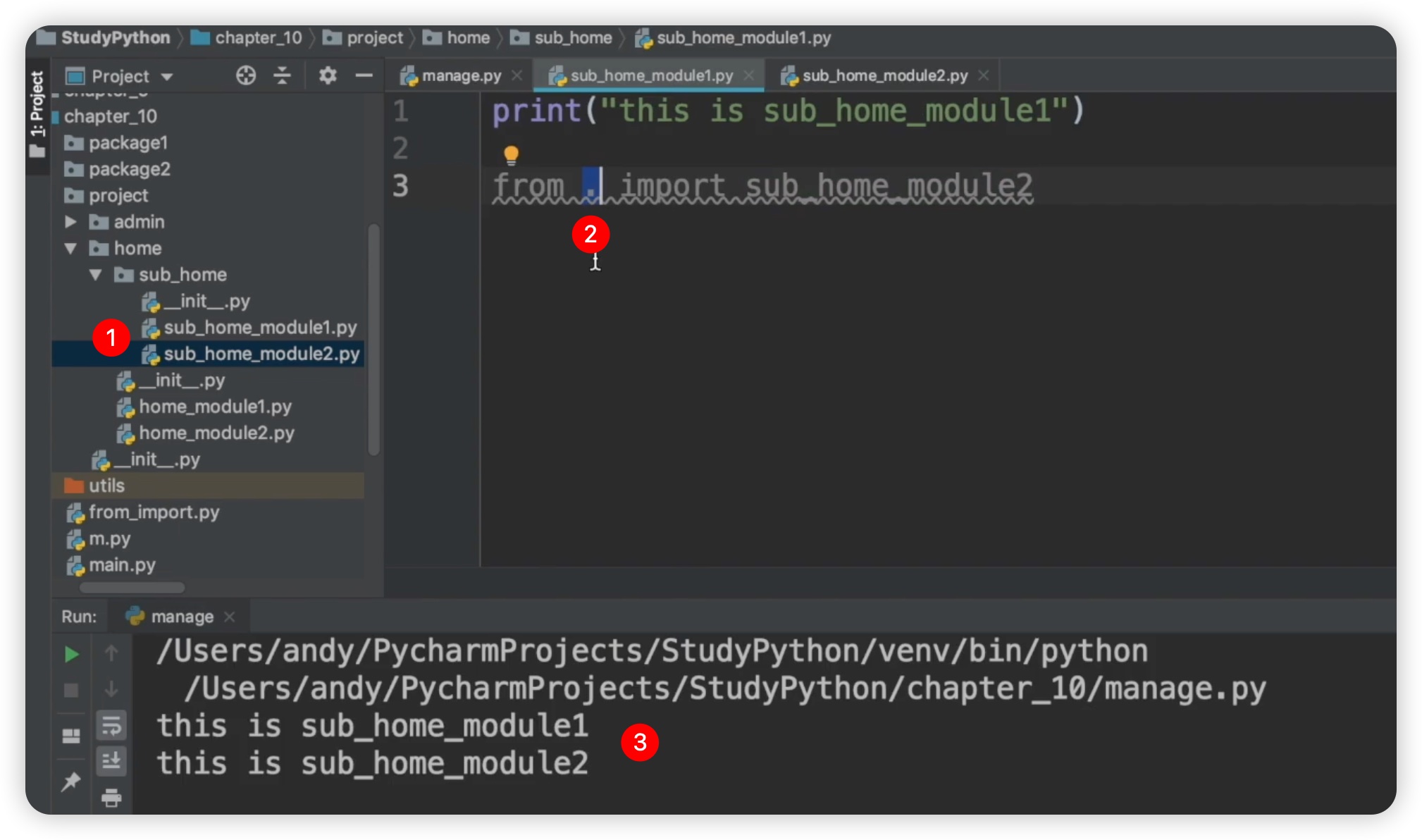
然后,我们再次运行"manage.py"文件,查看输出结果为"this is sub_home module1,this is sub_home module2"。尽管使用绝对路径是可行的,但是当目录层级较深时会变得非常繁琐。因此,针对这种情况,提供了一种新的方式,即使用相对路径。相对路径是相对于哪个文件的呢?这取决于你从哪个文件开始导入。在我们这个例子中,我们是从"sub_home module1"开始导入sub_home module2,所以需要找到sub_home module1.py的位置。这两个文件是在同一个路径下,因此在这里我们可以使用一个点号来省略前面的内容。最后,我们再次运行代码,结果应该与之前相同。这种形式使用了一个点号来省略前面的一大堆内容。如下图所示:
在这个案例中,"sub_home module2.py"相对于导入它的文件"sub_home module1.py"是在同级目录下,因此我们使用点号代替。但是,如果要导入的文件不在同一个路径下,比如要导入的文件是"home _module1",它们之间的关系就不再是同一路径了。在这种情况下,我们使用绝对路径来导入。代码如下:
# 输出字符串 "this is sub_home_modulel"
print("this is sub_home_modulel")
from project.home import home_module1
在"home module1.py"中,我们添加如下代码:
print("this is home_module1")
运行后,可以看到输出了"this is home_module1",这证明了绝对路径的使用是正确的。接下来我们尝试使用相对路径。由于"home_module1"相对于当前的"sub_home_module1"是在上一级目录,我们使用两个点号来表示上一级目录。代码如下:
# 输出字符串 "this is sub_home_modulel"
print("this is sub_home_modulel")
from .. import home_module1
同样地,运行manage.py后可以看到成功输出了相同的结果。从这个示例中,可以感受到使用相对路径的优势,它能够简化导入路径,特别是在项目目录结构较为复杂、层级较深时。
在使用相对路径时,一些学员经常会问道,如果直接运行"sub_home module1.py"会怎样?因为我们一直是在运行外层的文件"manage.py",将其作为项目的入口文件。那么如果直接运行"sub_home module1.py",能否正常运行呢?我们进行了尝试,结果直接运行时报错,提示导入错误,无法直接从"main"中导入"sub_home module2"。错误截图如下:
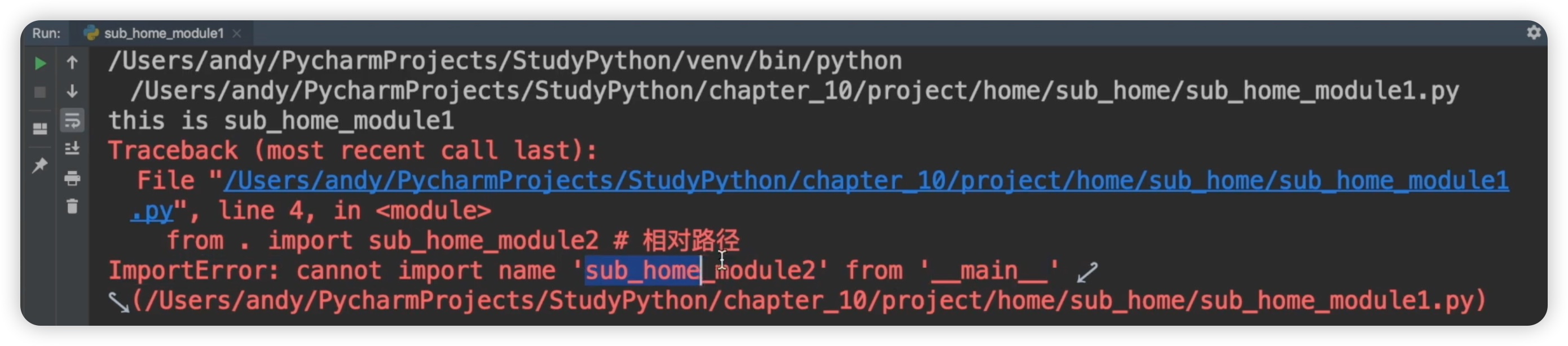
为什么会出现这样的错误呢?朋友们要记住,在本节开头我们提到过,相对路径和绝对路径是针对包而言的。不能直接运行包内的文件,因为不能将包内的文件视为主文件来运行。我们可以在包外的文件中导入包内的文件,但不能直接运行包内的文件。这是一个经常容易犯的错误,希望大家能够注意到这一点。